
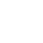

物体認識の原理(CNN編)
こんにちは。「毎日寒いなあ」と思いながら、道端で咲き始めている花を見て「もうちょっとの我慢」と思っている寒いの苦手な南野です。
最近、AIのソフト(EasyInspector2やDeepSky)をご使用頂いているお客様から「なんでこうなるの?」「こうなるはずでは?」「中身はどうなっているの?」というお話を頂くことが多くなっています。
このような時、担当者はどのように説明するべきか迷うようです。確かに、感覚的に分かりやすく説明しようとするといわゆる例え話(※)に終始してしまったり、細かく説明しようとすれば専門書の方が詳しいとなったりしてしまいます。私も「もう一歩踏み込んでAI画像処理の原理を知りたい」というお客様にちょうど良い説明資料が見つけられないでいました。
※社内でのお客様との会話で、「人間でも、同じものを別物と判断しなさいとか、同じものが2つあるのに一つは認識してもう一つは認識してはいけないと言われたら混乱しますよね。なのでアノテーションをするときは。。」という例え話を担当者が話しているのをよく耳にしています。
畳み込みニューラルネットワーク(CNN, Convolutional Neural Network)について調べた人はこんな図を色々なところで見たことがあると思います。
最近、AIのソフト(EasyInspector2やDeepSky)をご使用頂いているお客様から「なんでこうなるの?」「こうなるはずでは?」「中身はどうなっているの?」というお話を頂くことが多くなっています。
このような時、担当者はどのように説明するべきか迷うようです。確かに、感覚的に分かりやすく説明しようとするといわゆる例え話(※)に終始してしまったり、細かく説明しようとすれば専門書の方が詳しいとなったりしてしまいます。私も「もう一歩踏み込んでAI画像処理の原理を知りたい」というお客様にちょうど良い説明資料が見つけられないでいました。
※社内でのお客様との会話で、「人間でも、同じものを別物と判断しなさいとか、同じものが2つあるのに一つは認識してもう一つは認識してはいけないと言われたら混乱しますよね。なのでアノテーションをするときは。。」という例え話を担当者が話しているのをよく耳にしています。
畳み込みニューラルネットワーク(CNN, Convolutional Neural Network)について調べた人はこんな図を色々なところで見たことがあると思います。
英語版 Wikipedia「Convolutional neural network」より
https://en.wikipedia.org/wiki/Convolutional_neural_network
これはCNNの原理を図で表したものですが、これでは簡潔すぎて腹オチするところまでいかないのと、画像の1ピクセルが具体的にどの様に処理されていくかを説明するには不十分でもあります。
そこで、何かすごく分かりやすい図を使って説明できないものか、と説明資料を作るつもりでWeb上を探していたのですが、ズバリ分かりやすいサイトをあっさり見つけてしまいました(笑)。
画像の入力から結果(その物体は何なのか)の出力までが画像とマウス操作によるアニメーションで手に取るように(まさに1ピクセルごとに)わかる説明サイトです。このサイトでは説明のための画像を単にアップしているのではなく、TensorFlow.jsを使ってブラウザ内で実際に画像処理を行い、さらに各段階のデータを画像化して表示しています。自分が持っている画像をアップロードすることもできます。
CNN Explainer - Learn Convolutional Neural Network (CNN) in your browser!
https://poloclub.github.io/cnn-explainer/
そこで、何かすごく分かりやすい図を使って説明できないものか、と説明資料を作るつもりでWeb上を探していたのですが、ズバリ分かりやすいサイトをあっさり見つけてしまいました(笑)。
画像の入力から結果(その物体は何なのか)の出力までが画像とマウス操作によるアニメーションで手に取るように(まさに1ピクセルごとに)わかる説明サイトです。このサイトでは説明のための画像を単にアップしているのではなく、TensorFlow.jsを使ってブラウザ内で実際に画像処理を行い、さらに各段階のデータを画像化して表示しています。自分が持っている画像をアップロードすることもできます。
CNN Explainer - Learn Convolutional Neural Network (CNN) in your browser!
https://poloclub.github.io/cnn-explainer/

CNN Explainer の画面。クリックでサイトに移動します。
もうこのサイトでマウスを使って色々と試して頂ければ十分なのですが、せっかくなのでこのサイトの機能を使わせて頂き、「エスプレッソの画像がなぜエスプレッソであると判定されるのか?」について解説します。このサイトでは簡潔さのために分類は10種類、畳み込み層も4つのみです。ここからの私の解説も、簡潔さのために上記のような処理途中のデータを画像と呼びます(通常、処理途中のデータはデータであり、画像化はされません)。
畳み込みニューラルネットワーク(CNN, Convolutional Neural Network)の処理
ステップ1:画像入力
エスプレッソの画像です。カラー画像なのでRGBの3枚のモノクロ画像データに分解されます。

入力画像
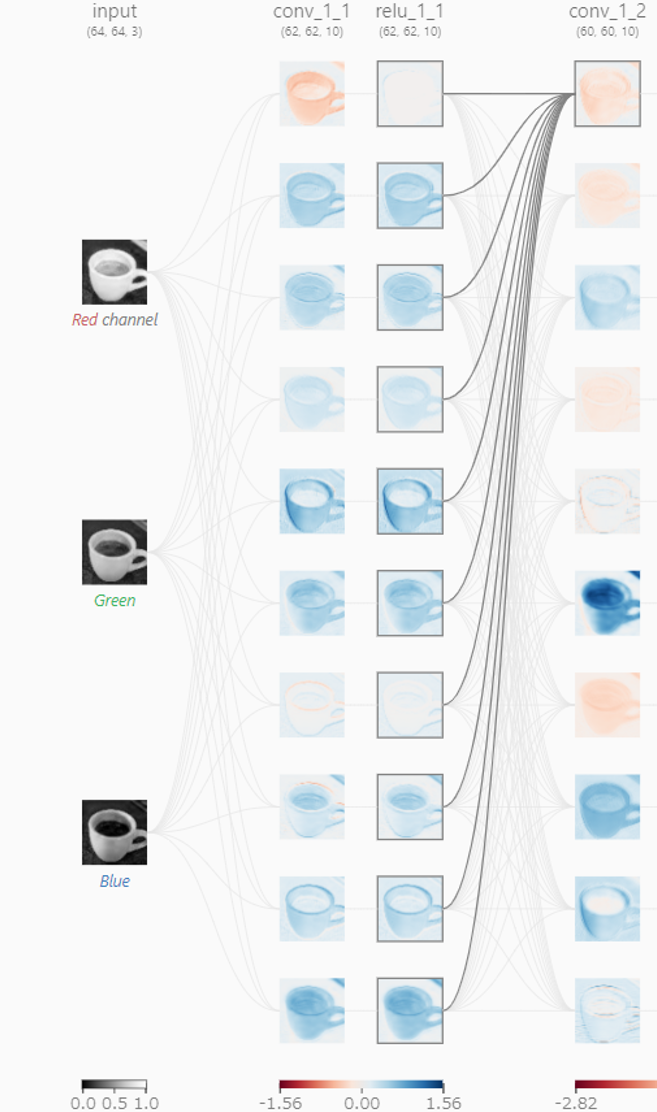
ステップ2:畳み込み
この3枚の画像を様々な方法(後述)で弄った10枚の画像に展開します。

10枚の画像に展開
はい、既にここで「なぜ10枚に展開するの?」と疑問に思うかもしれませんが、「1枚の画像を様々な角度から分析できるようにするために色々な弄り方をする」と思って頂ければよいと思います。では、「弄る」とは具体的に何をしているのでしょうか?
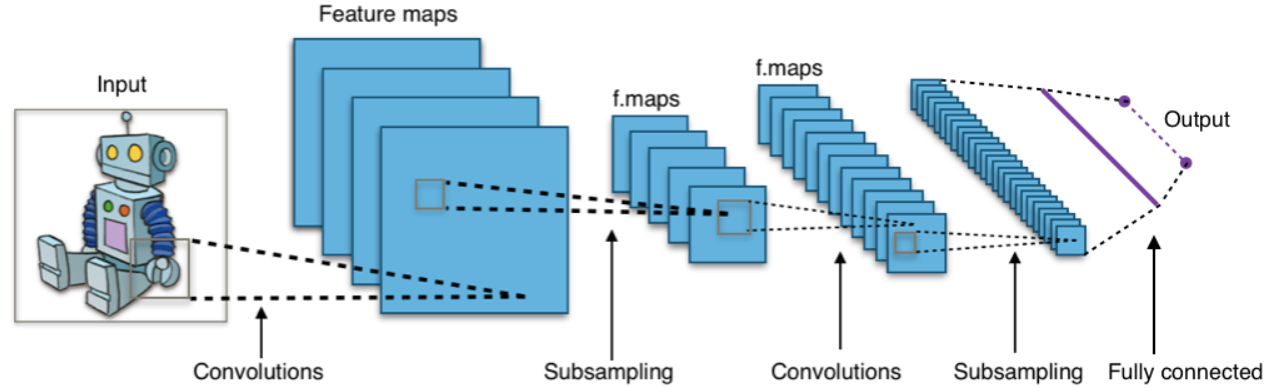
この「弄る」処理を畳み込み(Convolution)と言います。これがCNNのキモであり、ここだけ分かればだいたいの原理が分かったと言えると思います。下の図では、RGBそれぞれの画像を畳み込んで(詳細後述)それらを足し合わせたものを新たな画像として格納しています。
この「弄る」処理を畳み込み(Convolution)と言います。これがCNNのキモであり、ここだけ分かればだいたいの原理が分かったと言えると思います。下の図では、RGBそれぞれの画像を畳み込んで(詳細後述)それらを足し合わせたものを新たな画像として格納しています。
3枚の画像の畳み込みを行った後に足し合わせて新たな画像とする
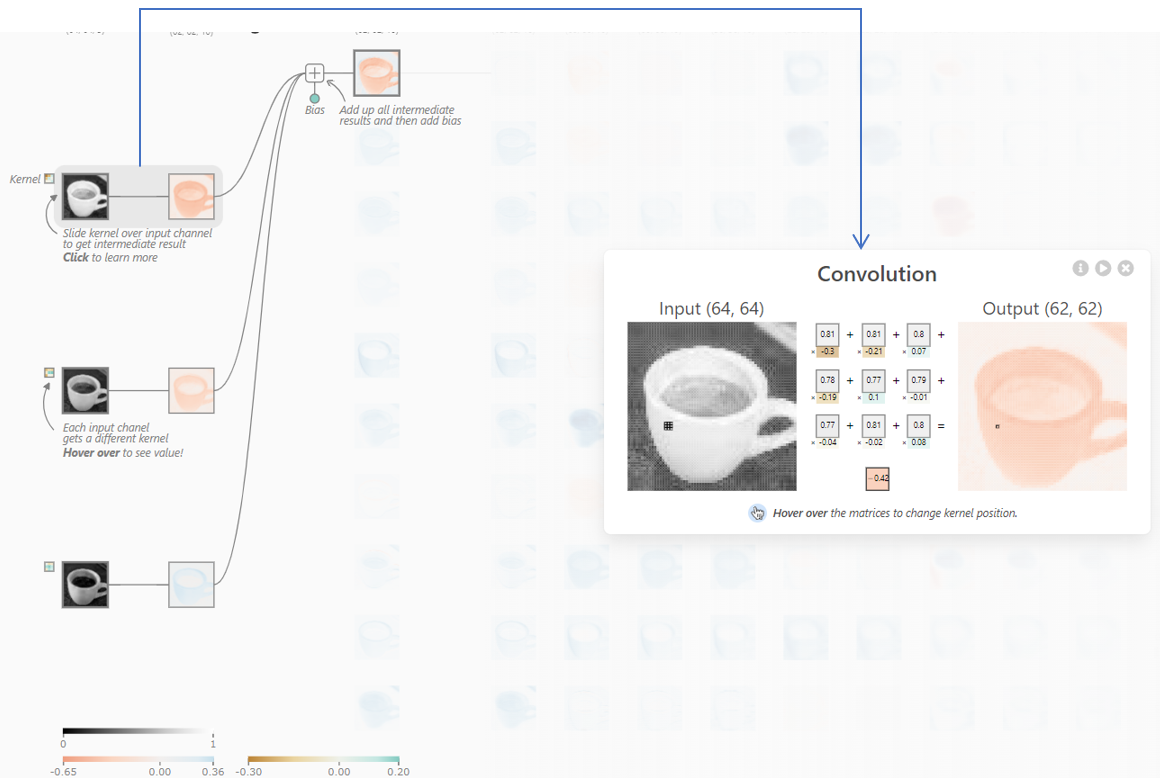
では、畳み込みとは具体的にどういう処理でしょうか?下の図を見て下さい。ここではRの元画像の左上から順に3x3の9ピクセルを取り出し、それに9通りの重み(赤枠部分, -1から+1)を掛けて足し合わせたものを出力の1ピクセルとしています。この9通りの重みの組み合わせをフィルターと言ったりカーネルと言ったりします。このサイトでは10種類のフィルターを使っているので10枚の画像に展開されているというわけです(10でなければいけないということはありません)。
3x3のフィルター(カーネル)を掛けて足し合わせる → 出力の1ピクセルへ
この「9通りの重み」は学習によって最適な数値が決められます。「最適な数値」とは「エスプレッソやバスの画像的な特徴をうまく取り出して見分けられるようにする数値」ということができます。例えば、見分けるための特徴が色なら特定の色を取り出すような数値の組み合わせ、見分けるための特徴が濃い直線ならそれを取り出すような数値の組み合わせということになります。畳み込みによって新たに作られた画像を「特徴マップ (Feature map)」と呼んだりする理由もここにあります。
画像を正しく分類するためのこれら数値の組み合わせは予め学習によって決めることになります(学習についてはまた別の機会に解説します)。この例では9個の重みデータ x RGB(3層)x 10画像出力なので この部分だけで270個の重みデータが使われています。実際に使用されている物体認識ではこの重みデータが全体で数百万といった数になります。
画像を正しく分類するためのこれら数値の組み合わせは予め学習によって決めることになります(学習についてはまた別の機会に解説します)。この例では9個の重みデータ x RGB(3層)x 10画像出力なので この部分だけで270個の重みデータが使われています。実際に使用されている物体認識ではこの重みデータが全体で数百万といった数になります。
ステップ3:ReLU(0戻し)
次の段階ではReLUという、マイナスの値になってしまったピクセルを0に戻す計算をしています。また、「なぜ?」と思うかもしれませんが、これはざっくり「学習の計算ができるようにするため」と考えればよいと思います。
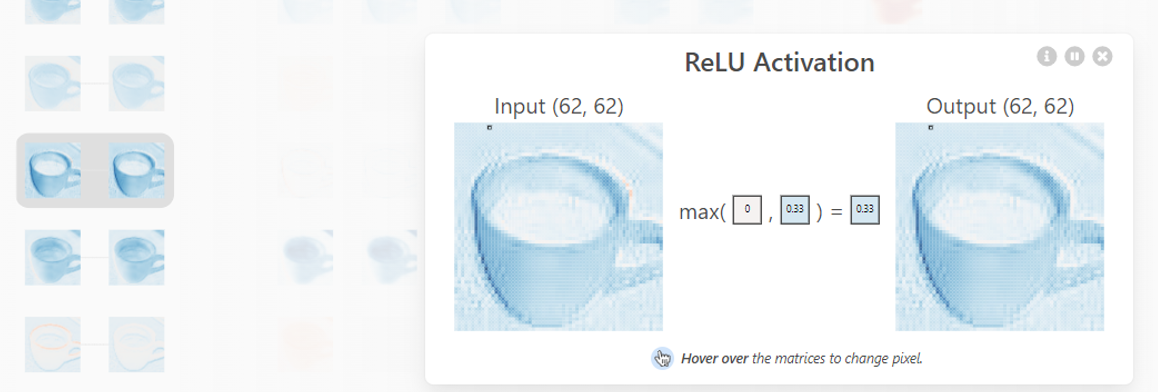
ReLUはマイナス値をゼロに戻す
ステップ4:さらに畳み込み
その後、この10枚の画像を先ほどと同じ方法で、ただし別の重みをつけながらさらに別の10枚の画像を作ります。ここでは 9個の重みデータ x 10枚の画像 x 10通りのフィルター = 900個の重みデータが使われています。これにより、さらに様々な角度から画像を分析できるようになりました。
畳み込み(2回目)
ステップ5:Max Pooling(最大値を取り出しながら画像を縮小)
そのあと、先ほどと同じようにReLU(0戻し)を通してMax Poolingという処理を行います。Max Poolingでは元画像の4ピクセルを取り出してその中の最大値を一つのピクセルデータとして抽出します。4ピクセルが1ピクセルになるので画像は小さくなります。Max Poolingの目的は「特徴的なデータは残しつつ画像を間引いて処理を速くすること」、と考えてください。

Max Poolingで2x2ピクセルの中の最大値を取り出す → 出力の1ピクセルへ
ステップ6:繰り返し
ここまでの処理を2回繰り返すことでさらに様々な角度から画像を分析できるようになります。使われている重みパラメータの数は 9 x (3 x 10 + 10 x 10 + 10 x 10 + 10 x 10) = 2,970になります。

繰り返して柔軟性を高める
ステップ7:フラット化(ピクセルを全て縦に並べる)
最後は10枚の画像の全ピクセルを縦に並べます。Max Poolingによって元々62x62ピクセルだった画像は13x13ピクセルにまで減少しています。10枚の画像なので全ピクセルを縦に並べると 10 x 13 x 13 = 1,690 データとなり、それぞれに重みづけをするので重みパラメータは 1,690 となります。
フラット化:全ピクセルを並べる
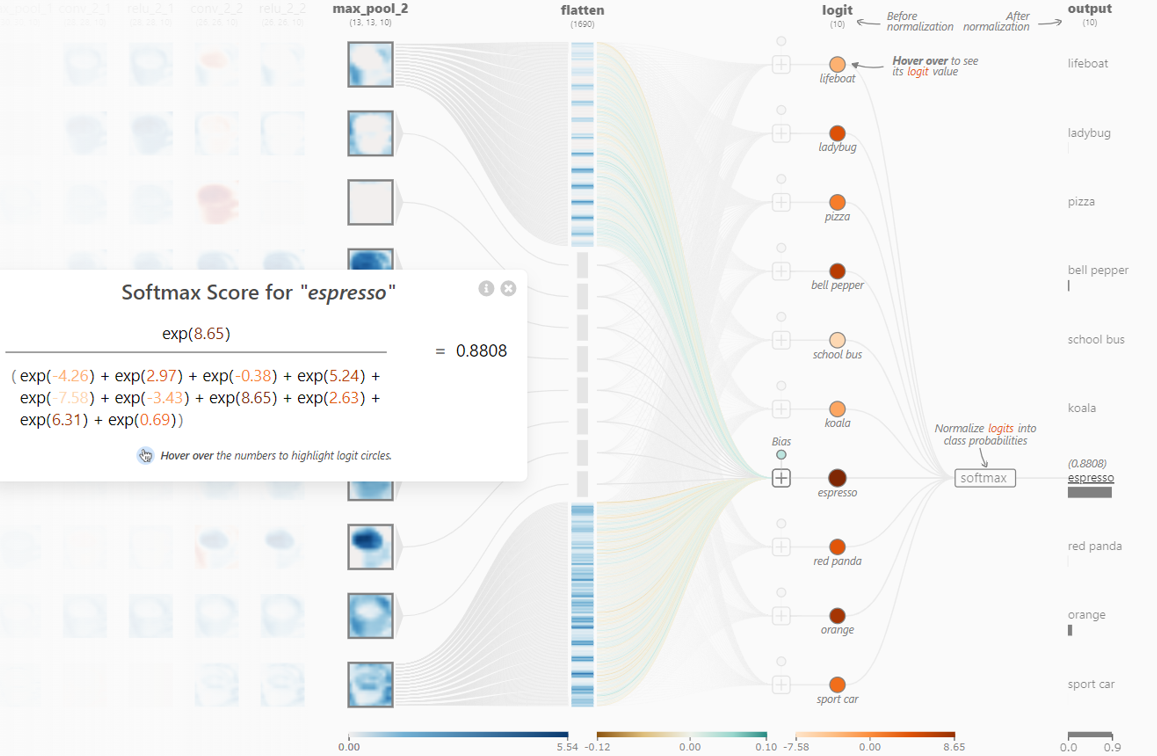
ステップ8:分類計算
これら1,690データを各分類クラス(ここではエスプレッソやピザ、バスなど)ごとに重みづけしながら足し合わせることで分類クラスの値が決まります。この値が最も大きなものが最終的に認識された物体となり、ここではエスプレッソが最大となっているので「これはエスプレッソです」という結果になります。ちなみに、ここではSoftMaxという計算をしていますが、これは学習させるときに必要になる計算方法であり分類結果自体は最大値を見ればOKです。

SoftMaxの計算
ここまでで元画像の入力から分類結果に至るまでの解説は終わりです。ここで使われた重みパラメータの合計数は4,660個。これだけのパラメータを使って画像を様々な角度から弄れば10種類の分類くらいはできそうな気がしてきませんか?そして、よく使われるモデルではこの1000倍のパラメータが使われます。
CNN前後の処理について
ここでは「CNN編」として画像を分類する部分のみについて書きましたが、実際の物体認識ではこの前段階で「物体らしきもの」を切り出す仕組み(Selective SearchやRegion Proposal Network)が働いていて、その仕組みから渡された画像をこのCNNで「この物体は○○」と分類しています。また、多くの物体認識では全ピクセルを縦に並べた後、さらに何層かのニューラルネットワークを挟むことで認識精度を向上させています。
様々なモデルの登場
層が深くなればそれだけ様々な画像に柔軟に対応できるようになります。そして、これら層の構成が様々なモデルの特徴(処理速度や精度)を形作っています。AI(ここではディープラーニングのこと)に関わる人々が層の構成や途中処理を工夫することで様々なモデルが作られ、1秒に何十枚も処理できる高速なモデルや小さな物体を発見できる高精度モデルなど、様々なモデルが作られています。スカイロジックの社員も様々なモデルを作っては壊す、という作業を日々繰り返しています。一晩中パソコンで学習を回すことも多く、朝出勤するとパソコンの排熱で室内が暑くなっていてびっくりすることもしばしばです。
まとめと謝辞
これまでの漠然としたAIのイメージから一歩踏み込んでピクセルごとの処理のイメージを描いて頂き、何かパラメータの数すごいな、とか、GPU使わなければならない理由はこれか、とか思ってもらえると嬉しいです。
後から気付いたのですが、このCNNの説明サイト「CNN Explainer」を作った人は私の母校の学生さんでした。力作を公開してくれた優秀な学生さんに感謝です。是非、実際のサイトでCNNを体験してみてください。
CNN Explainer - Learn Convolutional Neural Network (CNN) in your browser!
https://poloclub.github.io/cnn-explainer/
CNNを使って外観検査を行うソフトEasyInspector2はコチラです↓
https://www.skylogiq.co.jp/product/easyinspector/index.html
(2024.02.05)
後から気付いたのですが、このCNNの説明サイト「CNN Explainer」を作った人は私の母校の学生さんでした。力作を公開してくれた優秀な学生さんに感謝です。是非、実際のサイトでCNNを体験してみてください。
CNN Explainer - Learn Convolutional Neural Network (CNN) in your browser!
https://poloclub.github.io/cnn-explainer/
CNNを使って外観検査を行うソフトEasyInspector2はコチラです↓
https://www.skylogiq.co.jp/product/easyinspector/index.html
(2024.02.05)