

ディープラーニングにおける解像度の考え方
「検出力を向上するために高解像度のカメラを使いたい」というお声をよく頂きます。ルールベースの画像処理の場合高解像度の画像を使用すると一般的に検出力は向上しますが、ディープラーニングではその限りではない場合があります。ディープラーニングにおける解像度の大雑把な考え方を下記に簡単に解説致します。
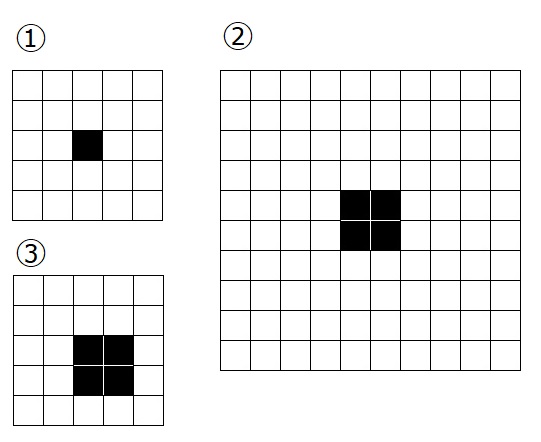
上の①~③のような画像があるとします。
①全体の面積5×5、黒い四角形の面積1
②全体面積10×10、黒い四角形の面積4
③全体の面積5×5、黒い四角形の面積4
②の黒い四角形の面積は①に比べて4倍大きいですが、全体の比率で見ればどちらも4%分しかありません。
この時ディープラーニングの検出上、①と②の結果はほとんど変わりません。
③は全体の面積は5×5しかありませんが、黒い四角は①よりも4倍大きく写っています。
全体の比率では16%あり、これは①に比べて検出力の向上が見込めます。
つまり検出力を向上したければ見つけたい物を、画角に対して単純に大きく写す必要があります。
ディープラーニングでは大きな面積の中から小さなものを見つけるというのが、実はちょっと苦手です。
(それでも結構な小ささまで認識してくれますが)
小さい物を見つける場合は最初から対象箇所を認識可能な大きさまで拡大して撮像するか、大きい画像を撮って後から分割して処理する方法で対応します。
①全体の面積5×5、黒い四角形の面積1
②全体面積10×10、黒い四角形の面積4
③全体の面積5×5、黒い四角形の面積4
②の黒い四角形の面積は①に比べて4倍大きいですが、全体の比率で見ればどちらも4%分しかありません。
この時ディープラーニングの検出上、①と②の結果はほとんど変わりません。
③は全体の面積は5×5しかありませんが、黒い四角は①よりも4倍大きく写っています。
全体の比率では16%あり、これは①に比べて検出力の向上が見込めます。
つまり検出力を向上したければ見つけたい物を、画角に対して単純に大きく写す必要があります。
ディープラーニングでは大きな面積の中から小さなものを見つけるというのが、実はちょっと苦手です。
(それでも結構な小ささまで認識してくれますが)
小さい物を見つける場合は最初から対象箇所を認識可能な大きさまで拡大して撮像するか、大きい画像を撮って後から分割して処理する方法で対応します。